The strongest open models now run on a box that fits on your desk, and they are nearly as good as the giants. The contrarian move in 2026 is to own the workhorse and rent the genius only when you actually need it.
By Kristian Kabashi
A few days ago a single government letter switched off the most powerful public AI model on Earth, for everyone, in an afternoon. I wrote about that already. What I want to talk about now is the lesson most people took from it, because I think it was the wrong one.
The common reaction was sensible and small. Get a backup vendor. If you are all in on one lab, sign up with a second so you have somewhere to fail over to. Fine advice, as far as it goes. But it misses the bigger thing sitting underneath, which is that almost every company building on AI right now is renting its brain, entirely, from a tiny handful of American labs. Switching from one landlord to another is not the same as owning your home. And for the first time, owning is actually on the table.
You are renting your brain from three landlords
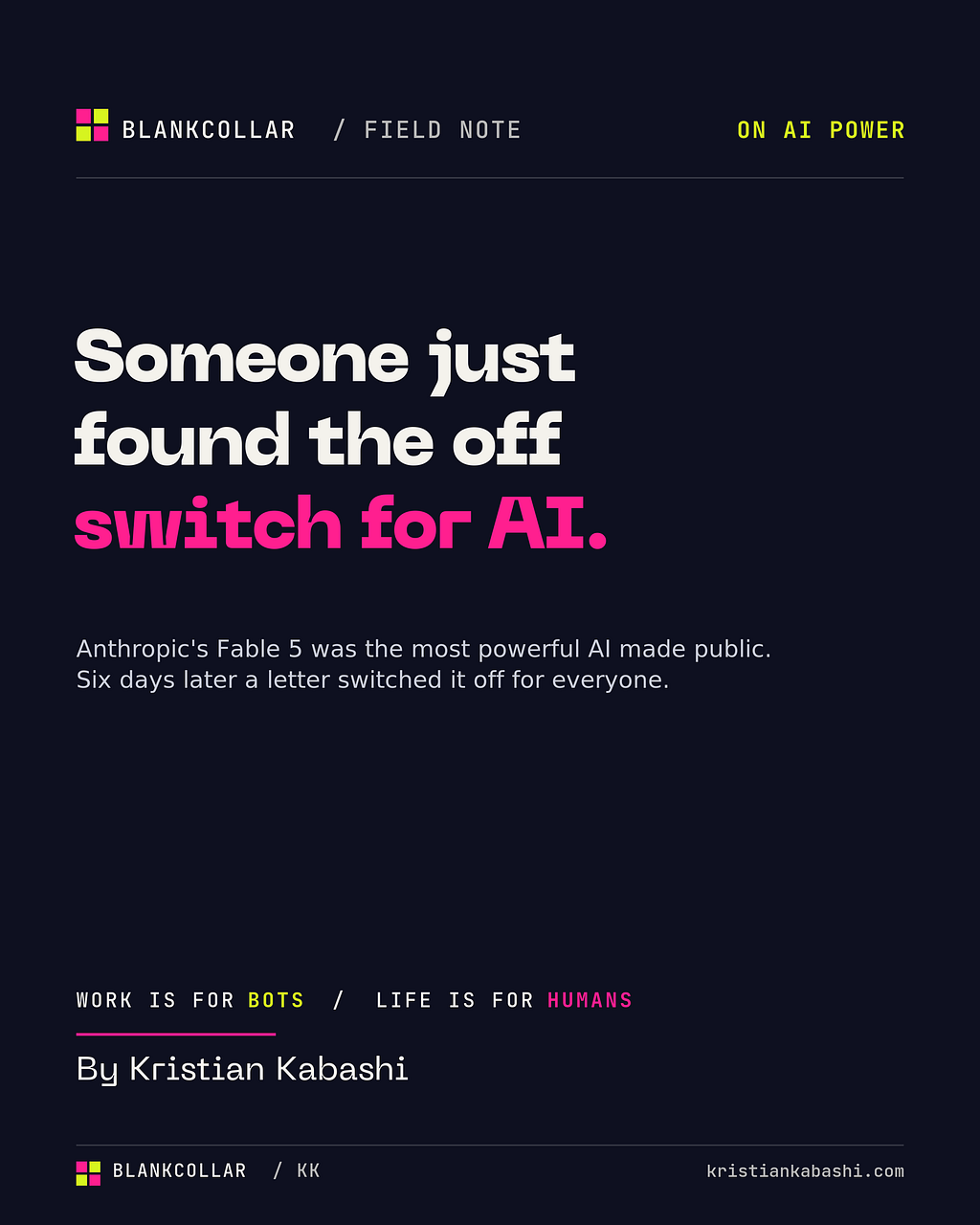
Look at where enterprise AI money goes and the picture is stark. By the end of 2025, something like 88 percent of enterprise spending on model APIs ran through just three providers, Anthropic, OpenAI and Google. The cloud underneath is barely less concentrated, with roughly two thirds of it sitting inside AWS, Azure and Google Cloud. So the core reasoning engine that more and more companies are wiring into the middle of how they operate, the thing that drafts the contract, triages the ticket, reads the scan, comes from maybe three or four phone numbers.
When something is that concentrated and that central, the risks stop being abstract. They have already happened. Azure’s OpenAI pricing jumped enough at one point to roughly double some customers’ bills overnight. OpenAI had an outage last June that froze business-critical workflows for the better part of a day. Models get deprecated on a schedule that suits the vendor, not you, with GPT-4 itself being retired from standard Azure deployments this year. And then, last week, a model got pulled entirely by government order. None of these were the customer’s fault, and in none of them did the customer have a say. That is what renting means. You do not hold the keys.
For a side project, who cares. For a company putting AI at the centre of how it works, total dependence on a few external providers you cannot control is a strategic risk, not an IT footnote. I think a lot of boards are about to realise this at the same time.
The thing that quietly changed
Here is what makes this more than a complaint. Two things shifted in the last year, and together they turn owning from a fantasy into a real option.
The first is that the open models got good. Not good for free models. Good, full stop. The gap between the very best American systems and the best openly available ones, many of them now coming out of Chinese labs, has mostly closed. Stanford’s AI Index has been tracking this, and the lead the top US model holds over the top Chinese one on the main public leaderboard has shrunk to a couple of percent, down from double digits two years ago. On the standard knowledge benchmark the gap was measured at a fraction of a percent by the end of 2024. The gap between open and closed models narrowed about as fast. And in April this year an open model from the Chinese lab Moonshot, Kimi K2.6, edged past the top OpenAI model on a hard real-world coding benchmark. An open file of weights, beating the flagship, on a task companies actually care about.
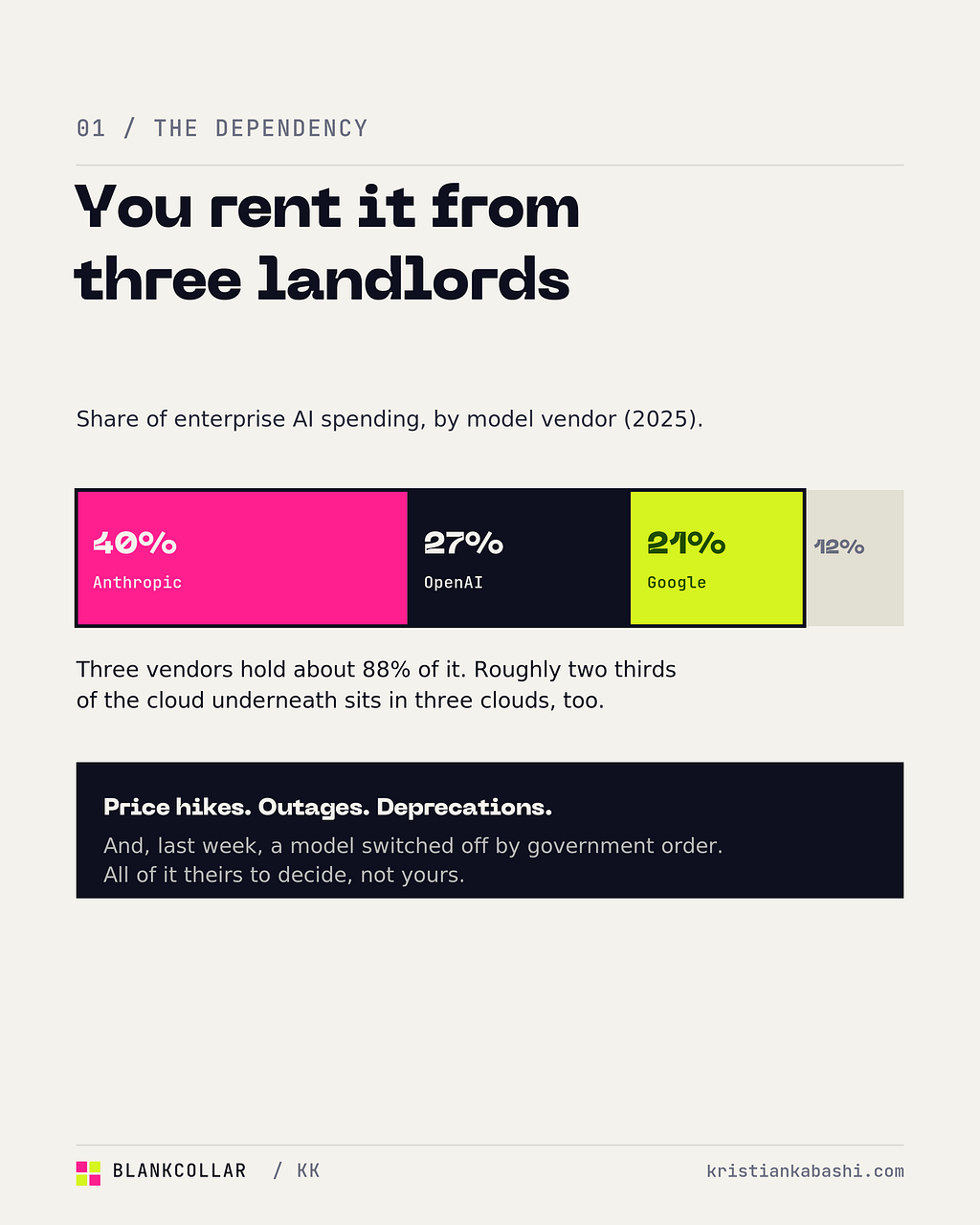
I want to be honest about the nuance, because the hype here gets ahead of the truth. The closed frontier still leads on the genuinely hard stuff, the deepest reasoning, the most agentic tool use, the tricky multimodal work, usually by something like five to ten percent and a few months. Benchmarks also get gamed, so I read any single score with one eyebrow up. But for the large majority of real work a company does, the open models crossed the line from “interesting” to “more than good enough” sometime in the last year, and most people have not updated on it yet. Crucially, the strongest of them ship as open weights under permissive licences, MIT and Apache, which is the part that matters next.

“But it is a Chinese model”
This is the objection I hear immediately, and it deserves a straight answer rather than a dodge. The worry is that using a Chinese model means sending your data to China. When you call a Chinese company’s API, that is a fair concern. But that is not what I am suggesting.
Open weights are just a file. When you run that file on your own hardware, the model does not phone home, because there is no home to phone. The data never leaves your building. It does not matter who trained the weights any more than it matters who wrote the open-source database your company already runs. You are not trusting the lab, you are running their output on your own metal, in your own basement, behind your own firewall. That is the whole sovereignty trick, and it flips the China question on its head. The open Chinese models are arguably better for your data sovereignty than a US API, precisely because you can download them and cut the cord.
And if it still sits badly, you have a growing menu of open models trained elsewhere. Meta’s Llama, France’s Mistral, OpenAI’s own open release, and, close to home for me, Apertus, a fully open model built last year by ETH Zurich, EPFL and the Swiss national supercomputing centre, trained across more than a thousand languages and released for anyone to run. A small country built its own public model precisely so it would not have to depend on anyone else’s. That should tell you where this is going.
The second unlock is the box on your desk
The other half of this used to be the dealbreaker. Even if you had the weights, running a serious model meant renting expensive cloud GPUs, which put you right back into renting. That changed too.
Late last year Nvidia started shipping a small Arm-based desktop machine, the DGX Spark, with 128 gigabytes of unified memory, enough to run open models up to around 200 billion parameters, for about four thousand dollars. It sits on a desk. It sips power. Link two together and you can run the really large ones. It is not the only option, there is an AMD-based box around two thousand, and Apple’s Mac Studio goes further on memory, but the point is the category now exists. A near-frontier brain you fully own, for the price of a decent laptop and a half.
The honest caveats matter, so here they are. These machines are limited by memory bandwidth, which means a big dense model runs at a polite reading pace rather than a blazing one, though the newer mixture-of-experts models, the architecture most of the strong open releases now use, run much better on them. They are for running models, not training them. And the raw speed is below what a cloud cluster gives you. But for a huge range of internal work, a box you own that answers in seconds and never sends a byte outside is a genuinely new thing. Two years ago this was a data-centre project. Now it is a purchase order.
Layer on the cost trend and it gets more interesting. The cost of running a model of a given quality has been, by one analysis from Andreessen Horowitz, “decreasing by 10x every year.” The hardware is a one-time capital cost. The running cost after that keeps falling. You pay more upfront and less, far more predictably, forever after.
The architecture that actually wins is hybrid
Now, I am not telling you to rip out the frontier APIs and run everything off a box in the server room. That would be its own kind of foolish, because the frontier really is better at the hardest things, and you want it there when you need it. The move is not all-or-nothing. It is a blend, and the blend is where almost nobody is yet.
Picture a router sitting in front of your AI. Every request hits it first. The routine, high-volume, sensitive work, which is most of it, goes to the open model you own and run in-house. The genuinely hard requests, the ones that need the absolute best reasoning, get escalated out to a frontier API. You rent the genius for the ten or twenty percent of work that truly needs it, and you own the workhorse for the rest.
This is not theoretical. A Berkeley project called RouteLLM showed a trained router cutting costs by around 85 percent while keeping about 95 percent of the top model’s quality, by sending only roughly a quarter of queries to the expensive model. The common rule of thumb people are landing on is to self-host the routine 80 percent and call APIs for the hard 20. In financial services, a sector that cannot exactly be cavalier about data, a recent survey found more than nine in ten leaders calling hybrid AI highly valuable and most of them already running it. They are doing this because more than half of enterprises now name data privacy as their single biggest blocker to using AI more, and a router architecture is how you stop choosing between capability and control.

When owning actually beats renting
I want to be careful here, because the honest answer is that owning does not always win, and anyone who tells you it always does is selling something.
If your AI bill is small, renting is cheaper. Full stop. Cloud providers have driven the price of running open models down to around ten or fifteen cents per million tokens, which is so cheap that buying and babysitting your own hardware would take years to pay back. Self-hosting also carries real hidden costs, the engineers, the maintenance, the unglamorous operational work of keeping a model serving reliably at 3am.
Owning starts to win in three situations, and they are becoming more common. When your usage is heavy and always-on, so the meter never stops and the capex amortises fast. When data sovereignty is not negotiable, which is the daily reality for healthcare, finance, law, defence and government, where the data legally cannot go to someone else’s cloud. And when you simply want predictable cost and no exposure to a kill switch, a price change, or a deprecation you did not vote for. The crossover point is real, but it is specific to you, so measure your own mix rather than trusting a vendor’s chart, including mine.
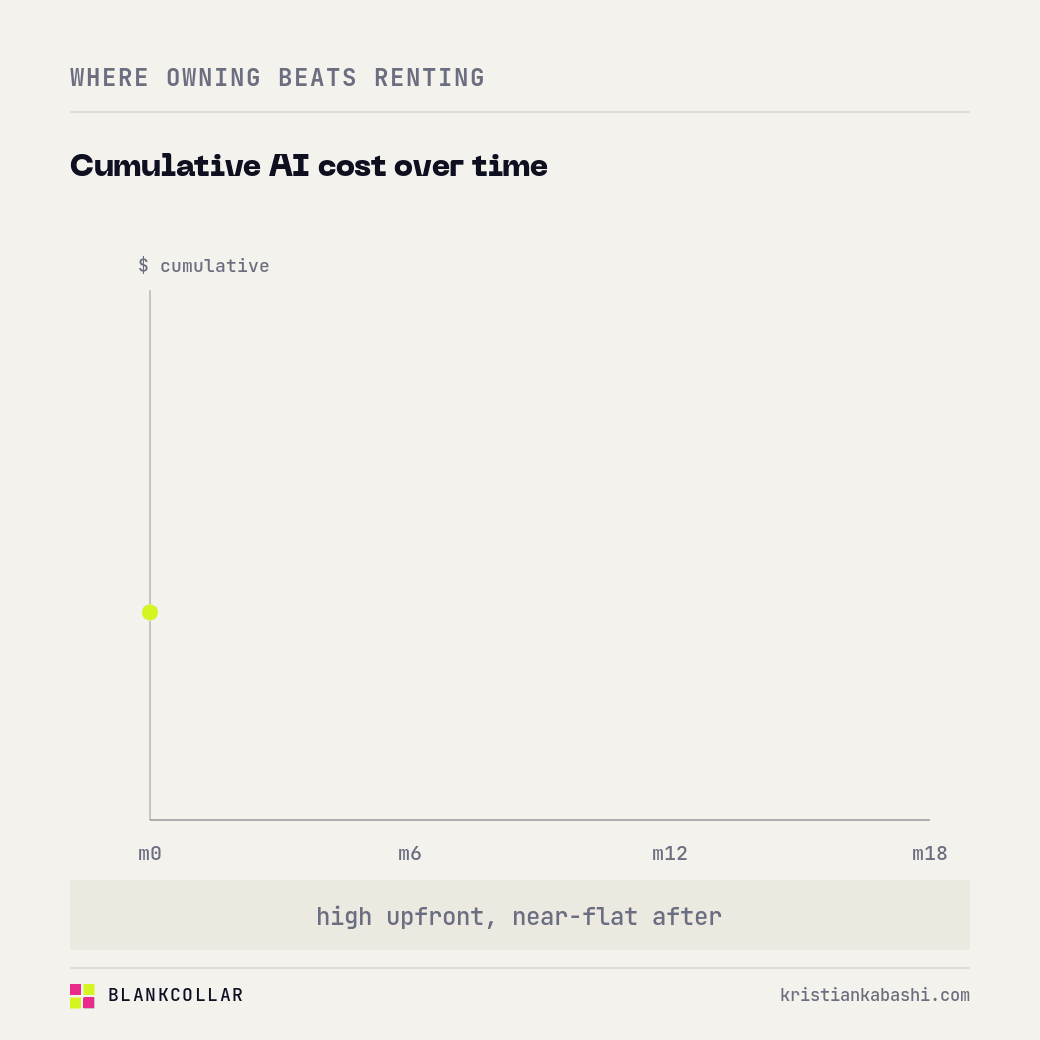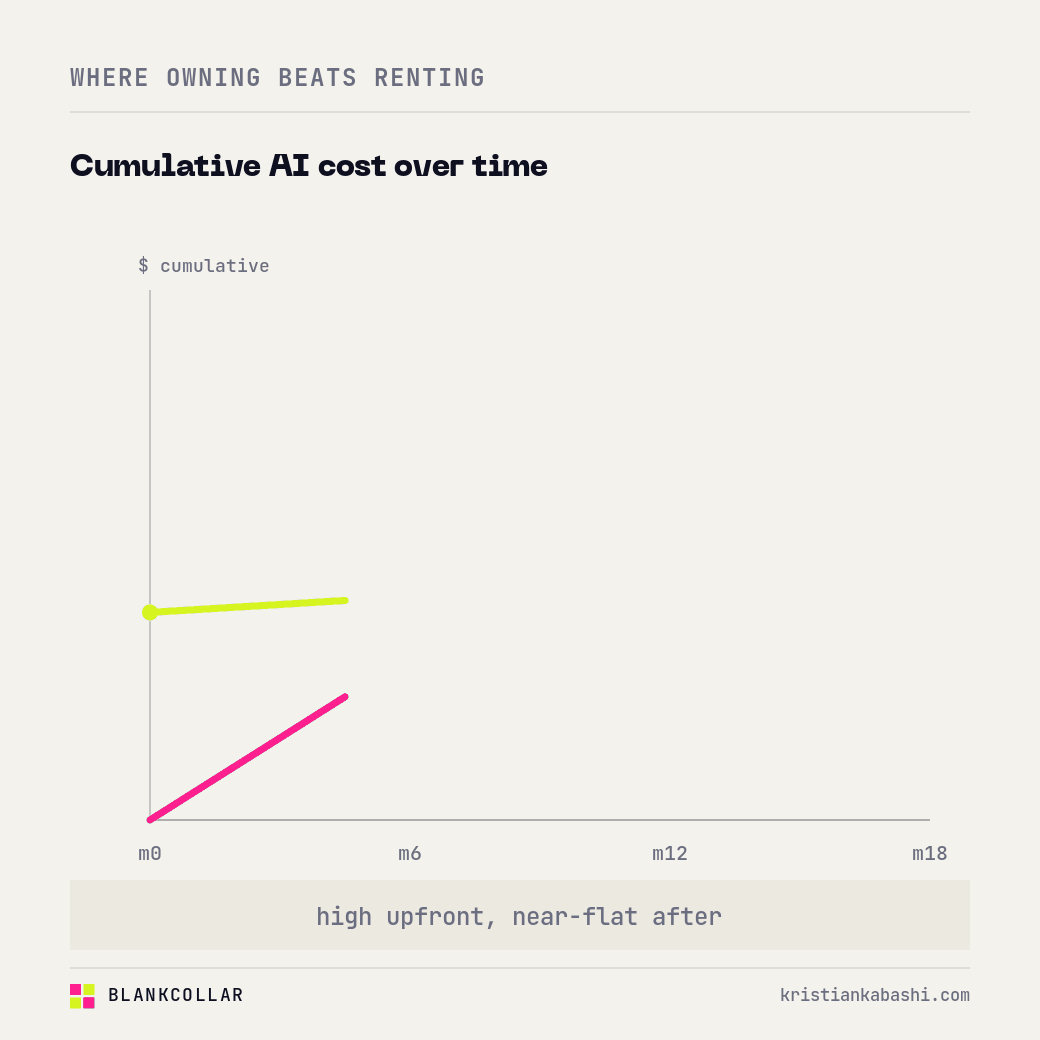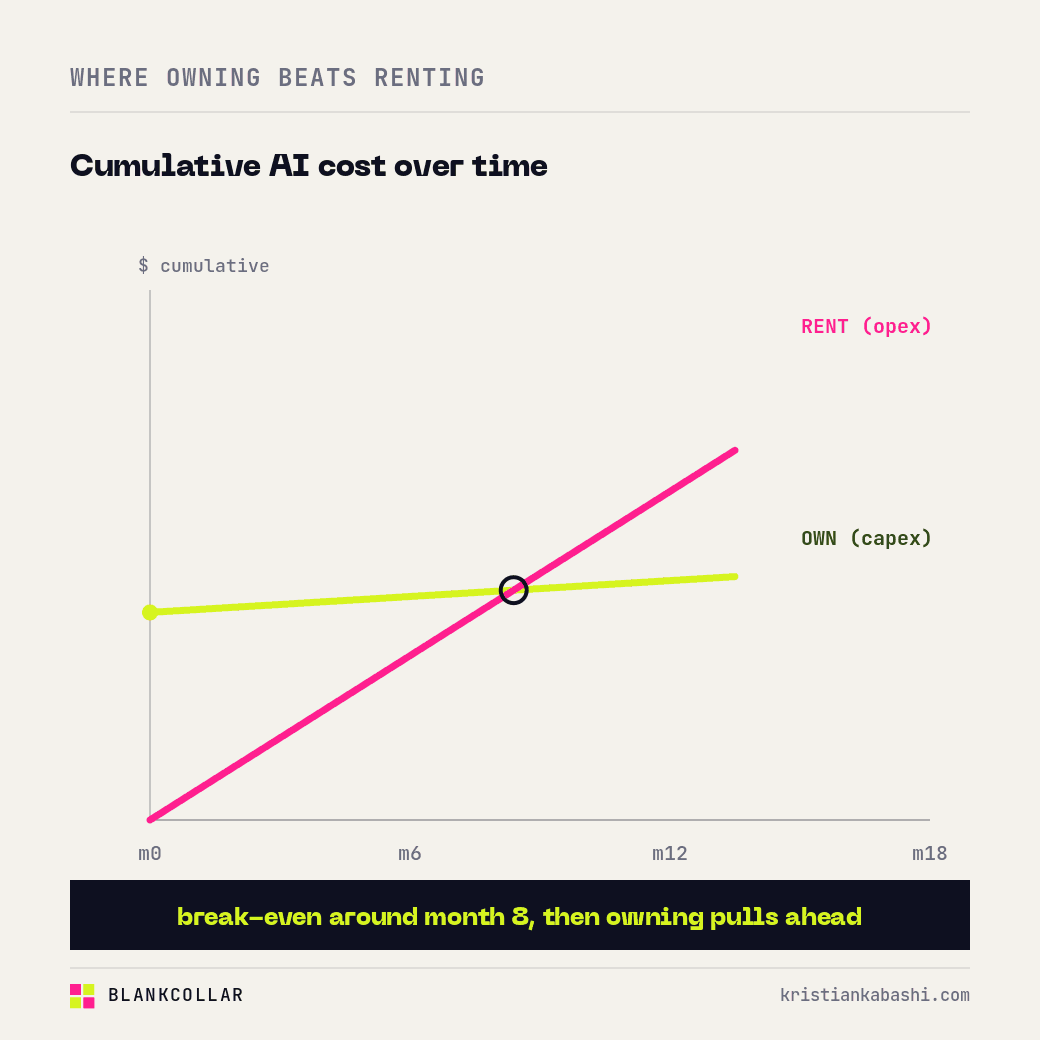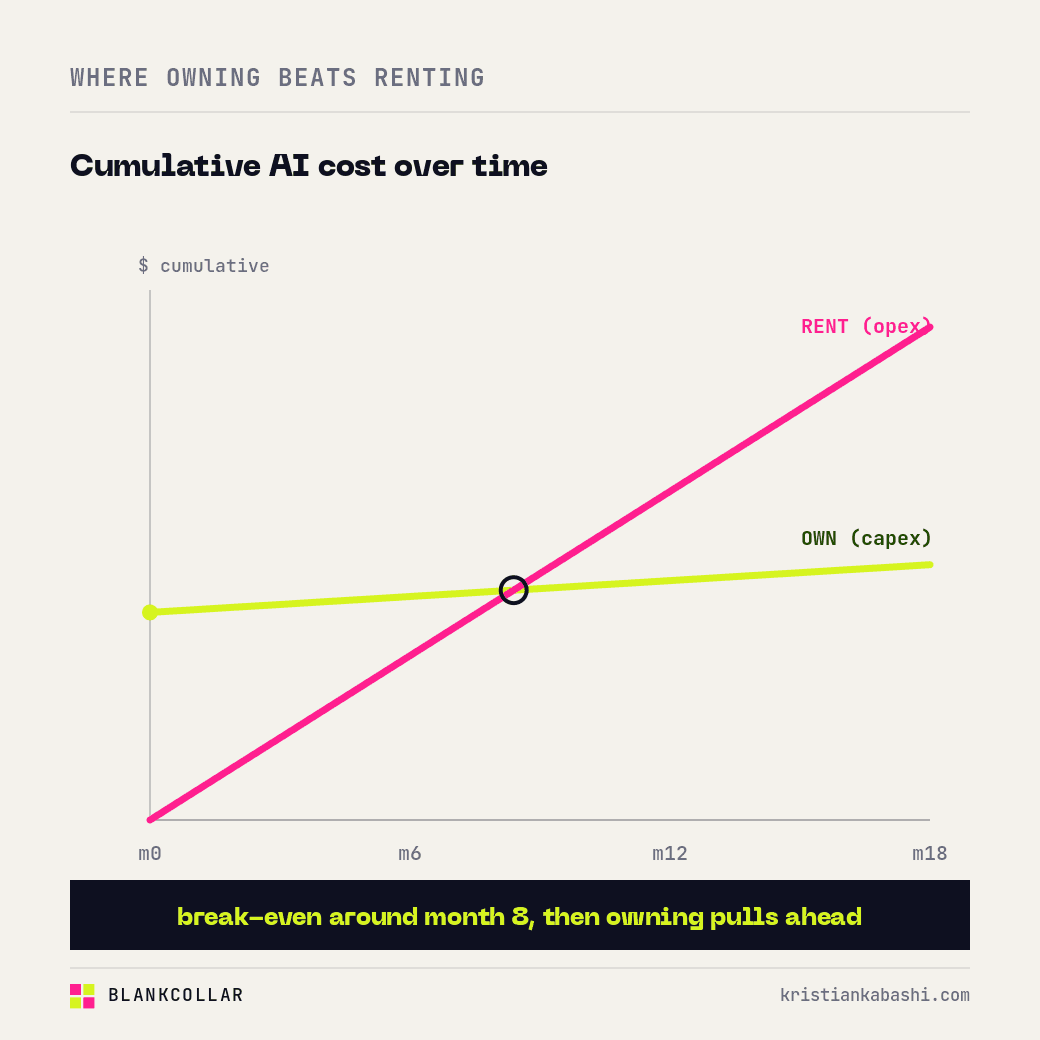
Sovereignty stops being a slogan
Step back and the direction is hard to miss. The European Union has put twenty billion euros behind building its own AI infrastructure, and late last year all twenty-seven member states signed a declaration naming dependence on foreign technology as a strategic risk in plain language. Gartner found that half of non-US technology chiefs now expect to change which vendors they use for geopolitical reasons, not technical ones. The market for sovereign cloud is forecast to grow several times over this decade. Switzerland built Apertus. None of this is fringe anymore. It is the slow, deliberate decision by a lot of serious institutions that the brain their society runs on should be one they actually control.
Companies are about to make the same decision, one budget cycle at a time. Not because owning is always cheaper, and not out of some flag-waving instinct, but because the events of the last year made the cost of pure dependence impossible to ignore. When you have watched a model get switched off by forces outside your control, the value of one you cannot lose becomes very easy to understand.
The reframe
The instinct of the last two years was to find the single smartest model and pipe everything to it. The instinct of the next two is going to be different, and I think sharper. The smartest model is worth surprisingly little if someone else can take it away from you on a Friday. The model you own, that runs on your hardware, on your data, on your schedule, might be five percent less brilliant and infinitely more dependable. For most of what a company actually does, that is the better trade.
So own the workhorse and rent the genius. Keep the routine and the sensitive in a model you control, reach out to the frontier only for the hard problems, and put a router in between so the whole thing is one system rather than a painful choice. You get most of the capability, most of the savings, your data stays home, and no single letter from anyone can take you fully offline.

Work is for bots. Just make sure that, for the work that matters most, the bots are yours.
Kristian Kabashi writes Blank Collar, a field guide for people building companies while the ground keeps moving. More at kristiankabashi.com.
Sources: Menlo Ventures, 2025 State of Generative AI in the Enterprise · Stanford HAI, 2026 AI Index takeaways · Stanford HAI, 2025 AI Index on the closing US-China gap · DeepSeek-V3 technical report · Qwen3 release · NVIDIA DGX Spark · Tom’s Hardware, DGX Spark price increase · a16z, LLMflation: inference cost decline · RouteLLM (Berkeley) · Cloudera/Finextra, hybrid AI in financial services · ETH Zurich, Apertus open model · Gartner, non-US CIO vendor survey